Introduction to data mining architecture
Data mining is described as a process of discovering or extracting interesting knowledge from large amounts of data stored in multiple data sources such as file systems, databases, data warehouses.
This knowledge contributes a lot of benefits to business strategies, scientific, medical research, governments, and individual.
Business data is collected explosively every minute through business transactions and stored in relational database systems.
In order to provide insight into the business processes, data warehouse systems have been built to provide analytical reports that help business users to make decisions.
Data is now stored in databases and/or data warehouse systems so should we design a data mining system that decouples or couples with databases and data warehouse systems?
This question leads to four possible architectures of a data mining system as follows:
No-coupling
In this architecture, the data mining system does not utilize any functionality of a database or data warehouse system.
The no-coupling data mining system retrieves data from a particular data source such as a file system, processes data using major data mining algorithms, and stores results into the file system.
The no-coupling data mining architecture does not take any advantage of a database or data warehouse that is already very efficient in organizing, storing, accessing, and retrieving data.
The no-coupling architecture is considered a poor architecture for data mining systems, however, it is used for simple data mining processes.
Loose Coupling
In this architecture, the data mining system uses the database or data warehouse for data retrieval.
In loose coupling data mining architecture, a data mining system retrieves data from the database or data warehouse, processes data using data mining algorithms, and stores the result in those systems.
This architecture is mainly for memory-based data mining system that does not require high scalability and high performance.
Semi-tight Coupling
in semi-tight coupling data mining architecture, besides linking to database or data warehouse system, data mining system uses several features of database or data warehouse systems to perform some data mining tasks including sorting, indexing, aggregation.
In this architecture, some intermediate results can be stored in a database or data warehouse system for better performance.
Tight Coupling
In tight coupling data mining architecture, a database or data warehouse is treated as an information retrieval component of a data mining system using integration.
All the features of a database or data warehouse are used to perform data mining tasks. This architecture provides system scalability, high performance, and integrated information.
Let’s examine the tight-coupling data mining architecture in greater detail.
Tight-coupling data mining architecture
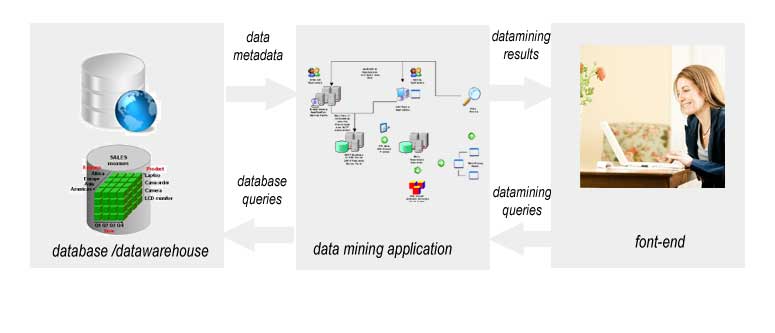
There are three tiers in the tight-coupling data mining architecture:
- The data layer: as mentioned above, the data layer can be a database and/or data warehouse system. This layer is an interface for all data sources. Data mining results are stored in the data layer so they can be presented to the end-user in the form of reports or another kind of visualization.
- The data mining application layer is used to retrieve data from the database. Some transformation routines can be performed here to transform data into the desired format. Then data is processed using various data mining algorithms.
- The front-end layer provides an intuitive and friendly user interface for end-user to interact with the data mining system. Data mining results presented in visualization form to the user in the front-end layer.
In this article, we’ve discussed various data mining architectures, their advantages, and their disadvantages. And then we looked into a tight couple of data mining architectures – the most desired, high performance, and scalable data mining architecture.